
【论文阅读】Adversarial Training with Fast Gradient Projection Method against Synonym Substitution Based Text Attacks
时间:2020
**作者:王晓森,杨逸辰等 **华中科技大学
会议:AAAI
总结:
做了什么?
提出了一种速度更快的,更容易应用在复杂神经网络和大数据集上的,基于同义词替换的NLP对抗样本生成方法,FGPM;
将FGPM纳入对抗训练中,以提高深度神经网络的鲁棒性。
怎么做的?
实验结果?
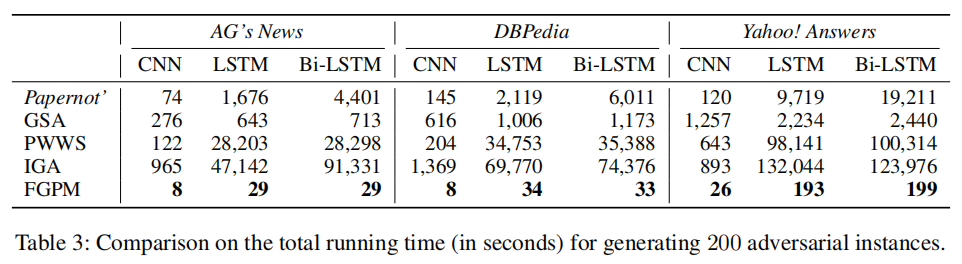
- FGPM的效果不是最高的,但也跟最高的差不多,但生成对抗样本的时间对比同类方法,缩减了1-3个数量级。
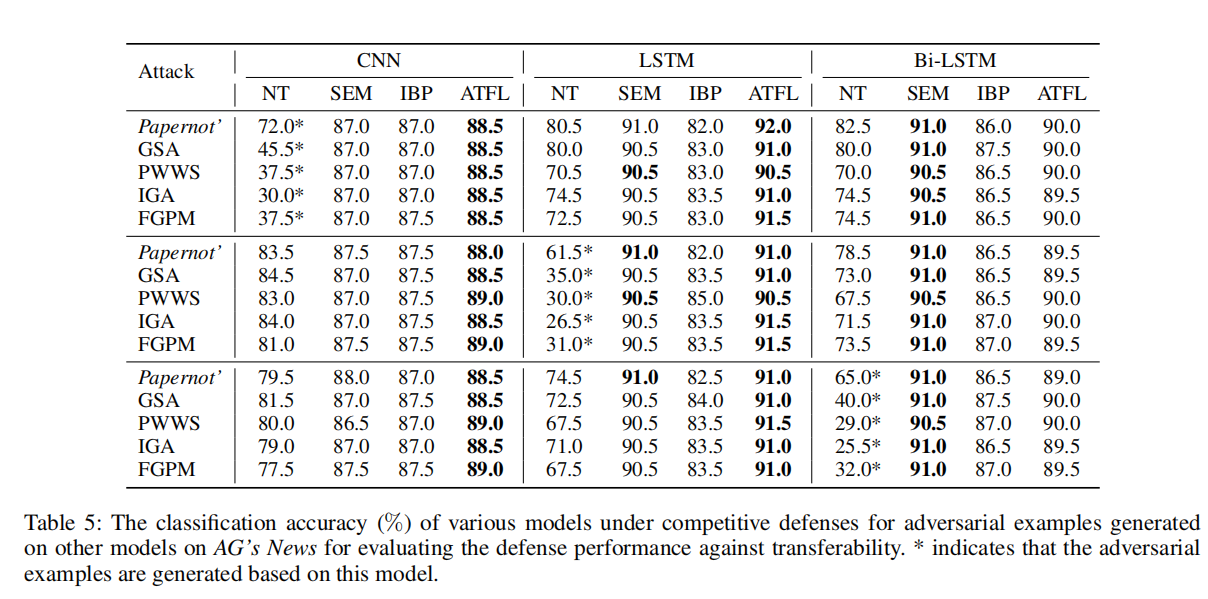
- ATFL的对抗样本防御能力和抗转移能力很强。
Abstract:
对抗训练是对于提升图像分类深度神经网络鲁棒性的,基于实验的最成功的进步所在。
然而,对于文本分类,现有的基于同义词替换的对抗样本攻击十分奏效,但却没有被很有效地合并入实际的文本对抗训练中。
基于梯度的攻击对于图像很有效,但因为文本的词汇,语法,语义结构的限制以及离散的文本输入空间,不能很好的应用于基于近义词替换的文本攻击中。
因此,我们提出了一个基于同义词的替换的快速的文本对抗抗攻击方法名为Fast Gradient Projection Method (FGPM)。它的速度是已有文本攻击方法的20余倍,攻击效果也跟这些方法差不多。
我们接着将FGPM合并入对抗训练中,提出了一个文本防御方法,Adversarial Training with FGPM enhanced by Logit pairing(ATFL)。
实验结果表明ATFL可以显著提高模型的鲁棒性,破坏对抗样本的可转移性。
1 Introduction:
现有的针对NLP的攻击方法包括了:字符等级攻击,单词等级攻击,句子等级攻击。
对于字符等级的攻击,最近的工作(Pruthi, Dhingra, and Lipton 2019)表明了拼写检查器很容易修正样本中的扰动;
对于句子等级的攻击,其一般需要基于改述,故需要更长的时间来生成对抗样本;
对于单词等级的攻击,基于嵌入扰动的替换(replacing word based on embedding perturbation),添加,删除单词都会很容易改变句子的语法语义结构与正确性,故同义词替换的方法可以更好的处理上述问题,同时保证对抗样本更难被人类观察者发现。
但不幸的是,基于同义词替换的攻击相较于如今对图像的攻击展现出了更低的功效。
据我们所知,对抗训练,对图像数据最有效的防御方法之一,并没有在对抗基于同义词替换的攻击上很好的实施过。
一方面,现有的基于同义词替换的攻击方法通常效率要低得多,难以纳入对抗训练。另一方面,尽管对图像的方法很有效,但其并不能直接移植到文本数据上。
1.1 Adversarial Defense:
有一系列工作对词嵌入进行扰动,并将扰动作为正则化策略用于对抗训练(Miyato, Dai, and Goodfellow
2016; Sato et al. 2018; Barham and Feizi 2019) 。这些工作目的是提高模型对于原始数据集的表现,并不是为了防御对抗样本攻击,因此,我们不会考虑这些工作。
不同于如今现有的防御方法,我们的工作聚焦于快速对抗样本生成,容易应用在复杂的神经网络和大数据集上的防御方法。
2 Fast Gradient Projection Method(FGPM):

3 Adversarial Training with FGPM:
具体算法中文描述见:
《基于同义词替换的快速梯度映射(FGPM)文本对抗攻击方法》阅读笔记 - 知乎 (zhihu.com)
4 Experimental Results:
我们衡量FGPM使用四种攻击准则,衡量ATFL使用两种防御准则。
我们在三个很受欢迎的基准数据集上,同时包括CNN和RNN模型上进行测试,代码开源:https://github.com/JHL-HUST/FGPM
4.1 Baselines:
为了评估FGPM的攻击效能,我们将其与Papernot’、GSA ( Kuleshov等人的4种对抗性攻击进行了比较。2018 )、PWWS ( Ren et al . 2019 )和Iga ( Wang,jin,and he 2019 )。
此外,为了验证我们的ATFL的防御能力,我们采用了SEM ( Wang,Jin,He 2019 )和IBP ( Jia et al . 2019 ),针对上述Word-Level攻击。由于攻击基线的效率很低,我们在每个数据集上随机抽取200个示例,并在各种模型上生成对抗样本。
4.2 Datasets:
AG’s News, DBPedia ontology and Yahoo! Answers (Zhang,Zhao, and LeCun 2015).
4.3 Models:
我们使用了CNNs,RNNs,来达到主流的文本分类表现,所有模型的嵌入维度均为300。
4.4 Evaluation on Attack Effectiveness:
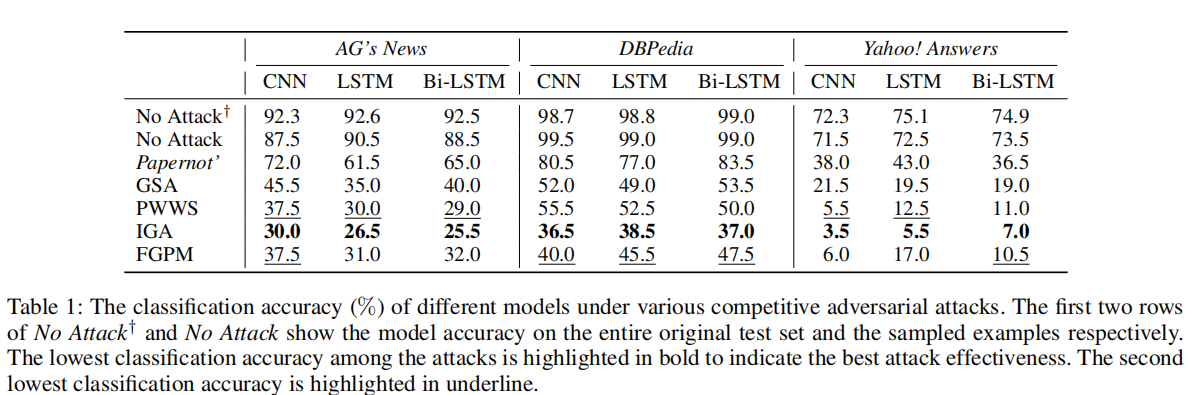
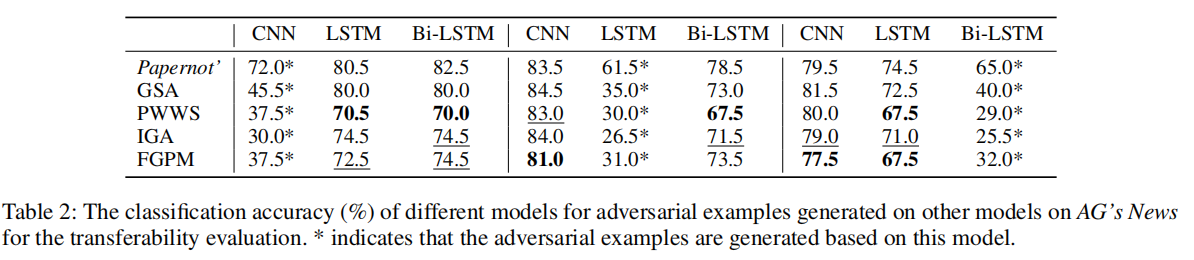
我们评估模型在攻击下的准确率和转移率:
准确率:
转移率:
4.4 Evaluation on Attack Efficiency:
对抗训练需要高效率的生成对抗样本以有效地提升模型鲁棒性。因此,我们评估了不同攻击方法在三个数据集上生成生成200个对抗样本的总时间。
4.5 Evaluation on Adversarial Training:
我们评估ATFL的对抗样本防御能力和抗转移能力:
对抗样本防御能力:

抗转移能力:
4.6 Evaluation on Adversarial Training Variants:
许多对抗训练的变体,例如CLP和ALP,TRADES等,已经尝试采用不同的正则化方法来提高针对图像数据的对抗训练准确率。
在这里,我们回答一个问题:这些变体方法也可以提高文本数据准确率吗?
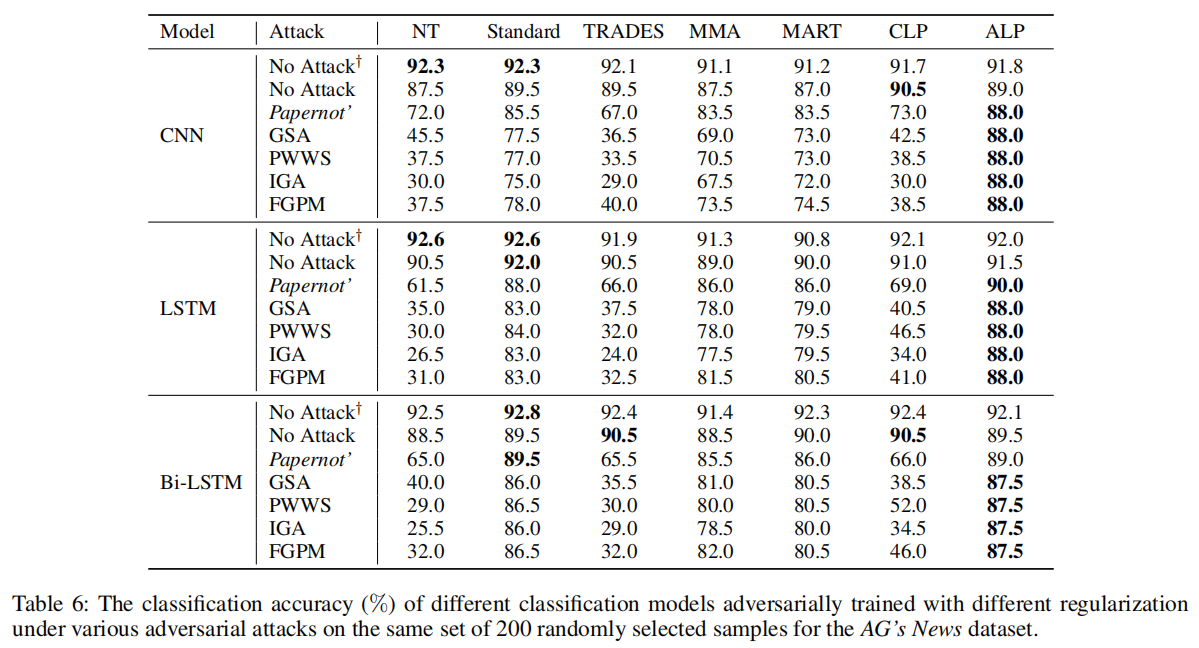
从表中可以看出,只有ALP可以长远地提升对抗训练的表现。